
AIビデオディレクター:NanoBananaのエージェントがあなたのアイデアを完全なビデオに変える方法
NanoBananaのAIビデオディレクターエージェントは、単一のpromptから、台本、キャラクター、シーン、ストーリーボード、最終的なビデオクリップまで、ビデオ制作パイプライン全体を自動化します。
まとめ
NanoBananaの新しいAIビデオディレクターエージェントは、一文のアイデアを入力するだけで、脚本の作成、キャラクターとシーンのデザイン、リファレンス画像の生成、ショットの分解、すべてのビデオクリップを並列で生成のために送信するという完全な制作パイプラインを自律的に実行します。タイムラインもツールも専門知識も不要です。
📌 主要なハイライト(10秒で読めます)
- ✅ 1つのチャットで完全なパイプライン: 脚本 → キャラクター/シーンアセット → ストーリーボード → ビデオクリップ
- ✅ 並列ビデオ生成: すべてのショットを同時に送信 → 1つずつ生成するより5倍高速
- ✅ キャラクターとシーンの整合性: リファレンス画像によりすべてのショットで視覚的な整合性を保てます
- ✅ 自動連続性チェック: ビデオ生成開始前にAIが不整合を検知して修正します
- ✅ 柔軟な開始ポイント: 任意の段階から作業を開始できる → 既に完了している作業はスキップ可能
- ⏱️ 読書時間: 5分
「テキストからビデオ」の課題
現在ほぼすべての大手AIラボがtext-to-videoを提供しています。promptを入力するとクリップが得られる。これは5秒以上の一貫性のある映像が必要になるまでは十分にシンプルです。
本当の課題は単一のクリップを生成することではありません。同じキャラクター、一貫性のあるロケーション、論理的なストーリーの展開、調整されたペーシングを持つ複数のショットからなるシーケンスを制作することです。これはプロのビデオ制作で常に求められてきたことであり、単一のtext-to-videoモデルだけでは実現できないことなのです。
ほとんどのクリエイターは苦痛な手動ループでこれに対処しています: クリップを生成 → promptを調整 → 再生成 → すべてのショットに対して繰り返し → キャラクターが依然として同じ外見になっていることを祈る。これは低速で、整合性がなく、創作的に疲れる作業です。
NanoBananaのAIビデオディレクターは、その手動ループを完全に置き換えるために開発されました。
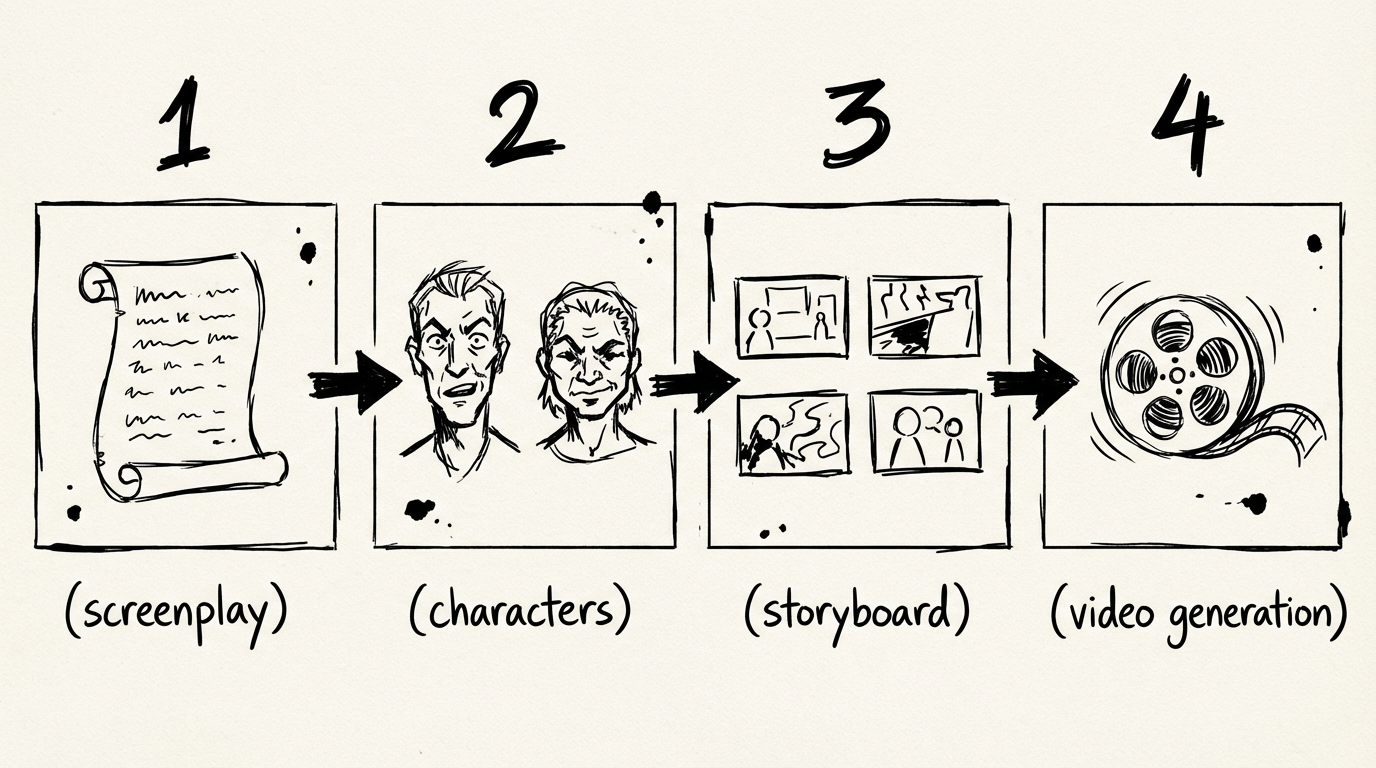
自動化された完全な制作パイプライン
AIビデオディレクターエージェントは、単一の会話内で4段階の制作パイプラインを実行します。各段階で正確に何が起こるかを説明します。
ステージ1 — 脚本: アウトライン、キャラクター、シーン
エージェントに1つのインプット、つまりあなたの創作的な目標を与えます。
"宇宙飛行士が火星でエイリアンからの信号を発見する30秒のスリラーを作ってください。"
エージェントのcreateScreenplayステップは、1回の呼び出しで同時に3つのものを生成します:
| 項目 | 得られるもの |
|---|---|
| ストーリーアウトライン | タイトル、あらすじ、テーマ、アクト構成(目標とする再生時間に合わせて調整) |
| キャラクター | 完全なプロフィール: 名前、役割、外見(画像生成用の視覚的な詳細)、性格、ストーリー上の成長 |
| シーン | ロケーション、時間帯、登場キャラクター、感情的なトーン、説明 |
すべての情報は1枚のカードにまとまっており、作業を進める前に確認できます。キャラクター数とシーン数はストーリーの規模に完全に依存し、エージェントが人工的に上限を設けることはありません。
💡 既に脚本をお持ちですか? ステージ1を完全にスキップして、ショットリストを直接貼り付けてください。エージェントはあなたの現在の作業状況から引き継ぎます。
ステージ2 — ビジュアルアセット: キャラクターリファレンス画像とシーン画像
ビデオを生成する前に、エージェントがあなたの制作のためのビジュアルライブラリを構築します。
- キャラクターリファレンス画像: ステージ1で作成した詳細な外見の説明から生成される、キャラクターごとの1枚の画像。これがそのキャラクターが登場するすべてのショットの視覚的な固定点となります。
- シーンリファレンス画像: 主要なロケーションごとの1枚の画像で、照明、環境、雰囲気の視覚的な言語を確立します。
これがAIビデオディレクターを単なるtext-to-videoツールと区別する点です。ビデオ生成モデルはリファレンス画像に固定されると、はるかに整合性の高い結果を生成します。同じキャラクターがショットごとに同じ外見になるのです。
ステージ3 — ショット分解: ストーリーボード
脚本とアセットが確定したら、エージェントが各シーンごとに詳細なショットスクリプトを生成します。
各ショットには以下が含まれます:
- ショットタイプ(クローズアップ、ミディアムショット、ワイドショット、POV、俯瞰)
- カメラアングルと動き
- ビデオ生成用に調整された視覚的な説明
- キャラクターのアクションとダイアログの指示
- 感情的なトーン
- 再生時間(選択したビデオモデルがサポートする長さに合わせて調整)
次にエージェントは自動的な連続性チェックを実行します。キャラクターの外見、ロケーションの論理、タイムラインの整合性に関する不整合について、ショットシーケンス全体をスキャンするのです。問題が見つかった場合、あなたに確認する前に自動的に修正し、最大2回まで再チェックを行います。
ステージ4 — ビデオ生成: すべてのクリップを並列で
確認後、エージェントが各ショットごとに最適化されたビデオ用promptを作成し、すべてを同時に送信します。
ここがアーキテクチャの違いが重要になる箇所です。ほとんどのワークフローでは1つのクリップを生成し、完了を待ってから次のクリップを生成します。NanoBananaのエージェントは並列送信を使用します。すべてのショットを一度にビデオプロバイダーに送信し、それぞれが独立してステータスをポーリングします。5ショットのプロジェクトの場合、5つのクリップの時間ではなく、1つのクリップと同じ時間で完了するのです。
各クリップカードは生成が完了するとリアルタイムで更新されます。クリップの準備ができるとインラインで表示されるので、ビデオライブラリに移動する必要はありません。
🎬 失敗した1ショットを再生成したいですか? シングルショットツールを使用して、他のクリップに影響を与えずにそのクリップだけを再実行できます。
これが他と違う点
実際の映像制作と同じように動作します
このパイプラインはプロの映像制作が実際に行われるプロセスを反映しています:コンセプト → キャスティング + ロケーション → ストーリーボード → 撮影。AIが各ステップ内のすべてのクラフト的な決定を処理しますが、この構造により各ステージが次のステージに影響を与えるようになっています — ステージ1で定義されたキャラクターはステージ3のショットの説明に表示され、ステージ2のロケーション画像がステージ4の視覚的なpromptを固定します。
柔軟で、硬直的ではありません
パイプラインはデフォルトの経路であり、必須ではありません。上級ユーザーは以下のことができます:
- 既存のシナリオがある場合、ステージ3から開始する
- アニメーションスタイルのビデオの場合、キャラクターアセットの生成をスキップする
- フルパイプラインを再実行することなく、単一のショットを再生成する
- コンパイルステップでビデオモデルまたは目標の再生時間を変更する
クレジットの消費量は予測可能です
確認する前に各ステージの固定コストが表示されます:
| ステージ | コスト |
|---|---|
| シナリオ(アウトライン + キャラクター + シーン) | 3クレジット |
| キャラクターリファレンス画像 | 1キャラクターあたり3クレジット |
| シーンリファレンス画像 | 1シーンあたり3クレジット |
| ショット内訳 | 3クレジット |
| ビデオ生成 | モデルと再生時間により異なります |
高額な処理(ビデオ生成)は、クレジットが請求される前に明示的な確認が必要です。いずれかのクリップの送信に失敗した場合、成功したクリップに対してのみ請求が行われます。
このツールは誰に向いていますか
単独でクリエイターをしている方:ストーリーのアイデアはあるが制作チームがいない場合。エージェントがすべてのクラフト的な決定を処理するので、各ステージで承認または調整するだけで済みます。
マーケティングチーム:プロダクトビデオ、ブランドスポット、ソーシャルコンテンツを大量に必要とする場合。ブランドキャラクターを一度定義すれば、無制限の制作でリファレンス画像を再利用できます。
開発者と代理店:AIによるビデオ制作をサービスとして提供したい場合。構造化されたパイプラインにより、出力結果が予測可能で、決定ポイントを追跡できます。
AIを試してみる映画制作者:フル撮影を行う前に叙事的なアイデアを早くテストしたい場合。ストーリーボードステージだけでも価値のある投資となります。
今すぐ試す
AIビデオディレクターはNanoBananaで公開されています。新しいチャットを開き、ビデオのアイデアを説明すると、エージェントがパイプラインを案内します。
クレジットが不足していますか?価格ページを確認してください — 900クレジットで20ドルから始まります。
よくある質問
フルパイプラインにはどれくらい時間がかかりますか?
シナリオの生成には30~60秒かかります。アセットの生成はキャラクターとシーンの数に依存します(1つあたりおよそ10~15秒)。ビデオの生成時間はモデルと再生時間により異なります — 通常1クリップあたり2~5分ですが、すべてのクリップが並列で送信されるため、総待機時間はすべてのクリップを合計した時間ではなく、1つのクリップの時間と同じになります。
生成された画像の代わりに独自のリファレンス画像を使用できますか?
はい。アセット生成ステージをスキップして、独自のリファレンス画像をビデオ生成の最初のフレームのアンカーとして提供できます。チャットで画像を説明すると、エージェントがコンパイルステップでそれらを使用します。
どのビデオモデルがサポートされていますか?
エージェントはNanoBananaで利用可能なすべてのビデオモデルに対応しており、Seedance 2.0、Veo 3.1 Lite、WAN 2.7などが含まれます。コンパイルステップでモデルを選択できます。モデルごとにサポートされる再生時間とクレジットコストが異なります。
短尺のビデオだけに対応していますか?
いいえ。シナリオステップで目標の再生時間に合わせてアクト数とシーン数を調整します。10秒のビデオの場合は1アクトと1~2シーンになります。2分のビデオの場合は3アクトと比例して多くのシーンになります。エージェントは、特に長めの制作を要求しない限り、コンパクトでインパクトのある制作を優先します。
ビデオクリップの生成に失敗した場合はどうなりますか?
セッション内で失敗したクリップはマークされます。パイプライン全体を再実行することなく、個々のショットを再試行できます。クレジットは正常に送信されたクリップに対してのみ請求されます。
アセットを生成する前にシナリオを編集する方法はありますか?
はい。ステージ1が完了すると、シナリオカードに完全なアウトライン、キャラクタープロフィール、シーンリストが表示されます。次のステージに進む前に、エージェントに自然言語で任意の要素を修正するよう依頼できます。
ビデオなしで画像のみを生成することはできますか?
もちろんです。直接Generate Imageツールは常に利用可能です——エージェントのパイプラインは必要ありません。エージェントに画像を生成するよう依頼すると、ビデオ制作ワークフローの外側で1ステップで処理されます。
連続性チェックはどのように機能しますか?
ショットの内訳が完了すると、エージェントがcheckContinuityを実行します。これはすべてのショットを順番に読み取り、以下のような問題をフラグで示すAIステップです:ショット間でキャラクターの髪色が変わる、夜のシーンの後に時間の移行なしに明るい昼間のシーンが続く、ショット間で小道具が消えるなど。問題は可能な場合は自動的に修正され、不可能な場合は報告されます。
続きを読む

AI Image Agent:1枚も100枚も、ツールを切り替えずに画像生成可能
NanoBananaのAI Image Agentは、単一のコンセプト画像からバッチスタイルトランスファーまで、1つのチャットですべて処理できます。promptのエンジニアリングは不要です。

PixVerse V6:シネマカメラコントロール、ネイティブオーディオ、15秒クリップ
PixVerseは2026年3月30日にV6をローンチしました。20種類以上のシネマカメラコントロール、ネイティブオーディオ同期、マルチショットエンジン、最長15秒の1080pネイティブ出力に対応しています。本記事では変更点と、あなたのワークフローに適しているかどうかを解説します。


PixVerse V6 対 V5.6:カメラコントロール、オーディオ、マルチショットエンジン
PixVerse V6は2026年3月30日に公開されました。V5.6と比較すると、20種類以上のシネマカメラコントロール、ネイティブオーディオ、マルチショットエンジンが追加され、1080pでのクリップ制限が15秒に引き上げられています。ここでは直接比較して解説します。