
Wan 2.7:阿里巴巴推出的支持首帧控制、可生成15秒视频的全新视频模型
Wan 2.7为阿里巴巴的开源视频模型系列带来了首/末帧控制、multi-reference视频输入以及基于指令的编辑能力。以下是它相较于Wan 2.6的所有更新内容。
太长不看:需要了解的5件事
- ✅ 首/末帧控制(FLF2V) — 设置开场和结束帧,Wan 2.7会自动补全两帧之间的动态画面
- ✅ 最多支持5个参考视频输入 — 导入多个参考片段,指导生成内容的人物、环境和动作风格
- ✅ 最长生成15秒视频片段 — 时长是早期Wan模型的3倍
- ✅ 基于指令的视频编辑 — 通过自然语言修改背景、光照或风格
- ❌ 暂无4K原生输出 — 最大分辨率为1080P;发布时暂未确认开源计划
什么是Wan 2.7?
Wan 2.7 是阿里巴巴通义实验室推出的最新视频生成模型,于2026年3月通过WaveSpeedAI API(wavespeed.ai)和阿里云DashScope平台开放使用,正式的GitHub发布仍待推进。
Wan是阿里巴巴旗下旗舰级开源视频生成模型系列。Wan 2.1基于Apache 2.0协议发布,获得了开发者群体的广泛采用。Wan 2.7是目前该系列能力最强的版本,新增了一系列早期版本不具备的专业级控制功能。
该模型基于 Diffusion Transformer + Flow Matching 架构构建,参数量估计约为270亿。它和当前一代高性能视频模型属于同一架构层级,使用潜在流匹配而非老旧的DDPM式扩散,生成速度更快、稳定性更高。
和Wan 2.6相比有哪些变化
Wan 2.7不是一个小补丁更新,以下是实际的功能差异:
| 功能 | Wan 2.6 | Wan 2.7 |
|---|---|---|
| 文生视频 | ✅ | ✅ |
| 图生视频 | ✅ | ✅ |
| 首/末帧控制(FLF2V) | ❌ | ✅ |
| 多参考视频输入 | ❌ | ✅ (最多5个) |
| 九宫格图像输入 | ❌ | ✅ |
| 基于指令的视频编辑 | ❌ | ✅ |
| 多语言唇形同步 | ❌ | ✅ |
| 最大片段时长 | ~5秒 | 15秒 |
| 最大分辨率 | 1080P | 1080P |
本次新增功能的幅度很大。首/末帧控制、multi-reference输入和指令编辑都是Wan 2.6不具备的专业工作流能力。
核心新功能详解
首/末帧控制 (FLF2V)
FLF2V允许你自定义视频的首帧和末帧,再由Wan 2.7生成两帧之间的动态内容。这对商业创作来说是非常实用的控制功能:你可以设定特定的起始构图,指定镜头的最终终点,让模型处理中间的相机和主体运动。
适用场景:
- 产品镜头,需要产品从居中位置开始,最终转到特定角度
- 角色动画,需要两端的姿势完全符合要求
- 两个固定构图之间的电影级转场
多参考视频输入
Wan 2.7最多同时支持5个参考视频输入。模型会读取参考视频的信息,保证生成片段中人物一致性、环境风格和运动模式符合要求。这比单图参考更成熟,解决了视频生成长期以来的一个痛点:人物外观在镜头中无法保持一致。
在商业使用中,这意味着你可以提供产品运动方式、人物外观或目标环境风格的示例,模型会将这些上下文应用到新的生成内容中。
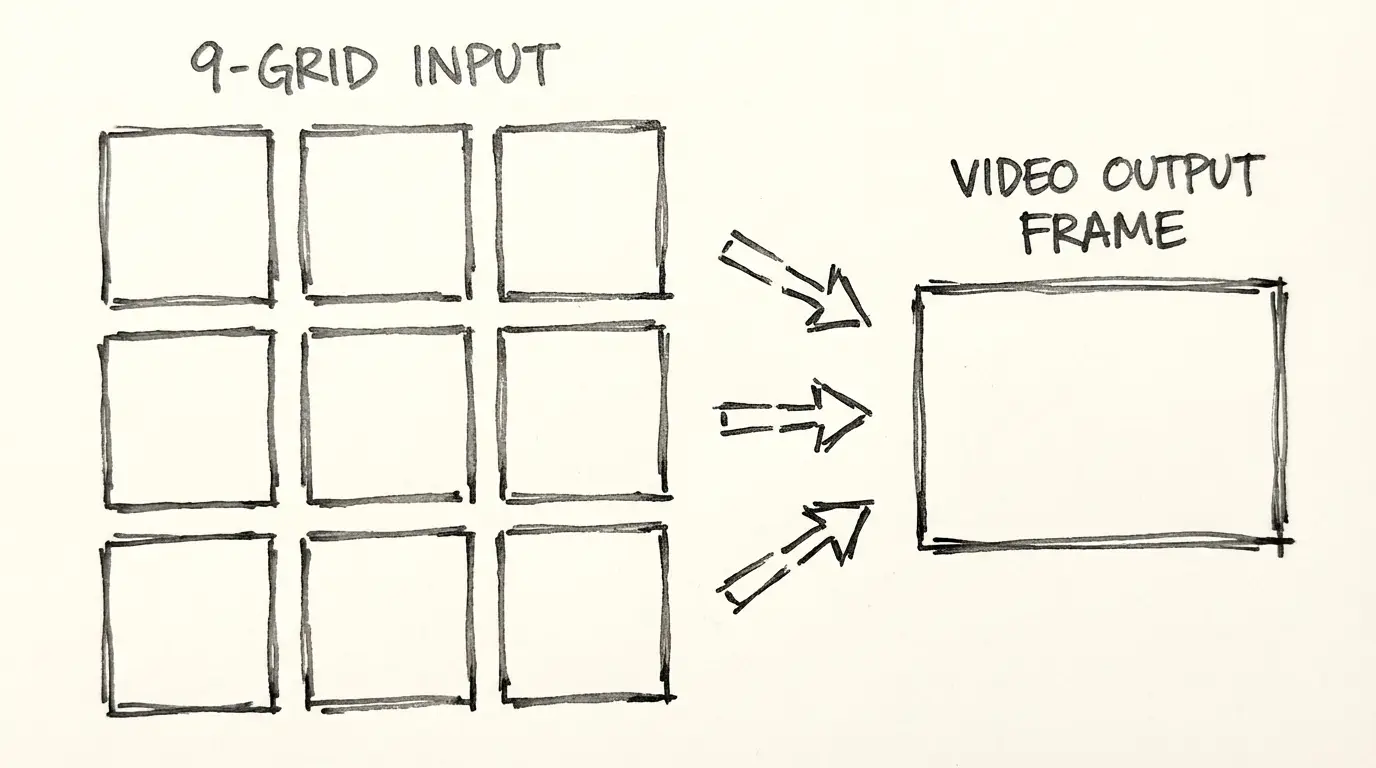
九宫格图像输入
九宫格输入支持将3×3排列的图像作为单个输入。模型会读取全部9帧,从多个角度理解上下文、人物或环境信息。这对于需要保证人物一致性的场景尤其有用,单张参考图往往无法捕捉足够的细节。
基于指令的视频编辑
Wan 2.7不需要从头重新生成,支持通过自然语言指令修改已有视频。你可以描述想要修改的内容——背景颜色、光影氛围、主体服装或视觉风格——模型会在保留原始运动的前提下应用修改。
这大幅降低了商业视频制作的迭代成本,对已经确认的动态内容进行小调整是行业常见需求。
多语言唇形同步
Wan 2.7新增了多语言唇形同步支持,生成的人物说话动画可以和不同语言的音频对齐,这对本地化工作流来说是非常实用的功能。
技术规格
| 规格 | Wan 2.7 |
|---|---|
| 架构 | Diffusion Transformer + Flow Matching |
| 参数量 | ~270亿 (预估) |
| 分辨率 | 480P, 720P, 1080P |
| 时长 | 2–15 秒 |
| 宽高比 | 16:9, 9:16, 1:1 |
| 模式 | T2V, I2V, FLF2V, 指令编辑 |
| API接入 | WaveSpeedAI, 阿里云DashScope |
| 开源 | 计划Apache 2.0协议 (发布时状态待定) |
| 处理时间 | 生成一个5秒1080P片段约需30秒到2分钟 |
已知局限性
没有完美的模型,以下是Wan 2.7目前不具备的能力:
- 暂无4K原生输出。 最大分辨率为1080P。如果你需要4K用于数字标牌、电影预演或大屏幕显示,你需要使用其他模型,或在后期进行升采样。
- 发布时未确认开源计划。 Wan 2.1曾基于Apache 2.0协议完全开源。撰写本文时,Wan 2.7的开源状态尚未正式公布,请查看Alibaba Wan GitHub获取最新信息。
- 未公布官方定价。 请前往WaveSpeedAI和DashScope平台查询对应API定价,参考基准是Wan 2.6的API费率,但Wan 2.7的定价可能不同。
- 属于新模型,社区测试有限。 Wan 2.7发布时间较短,旧模型拥有的广泛社区测试仍在积累中。
如何使用Wan 2.7
方案 1:使用 NanoBanana(无需配置 API)
前往 NanoBanana 上的 Wan 2.7 视频生成器,输入 prompt,选择时长和宽高比后即可生成。无需 API 密钥或 DashScope 账号。
方案 2:WaveSpeedAI API
在 wavespeed.ai 创建账号,Wan 2.7 已开放 API 端点调用。发送 POST 请求,携带你的 prompt、模式(T2V 或 I2V)、时长(2–15 秒)、分辨率(480P、720P、1080P)和宽高比即可。
方案 3:阿里云 DashScope
如果你已经在使用阿里云服务,可以通过 DashScope API 访问 Wan 2.7。使用 DashScope 控制台生成 API 密钥,即可在请求中调用 Wan 2.7 模型。
常见问题
立即体验 Wan 2.7
→ 使用 Wan 2.7 生成视频 — 基于 text-to-video 和 image-to-video,无需配置 API。
信息披露
本文中的模型信息和功能描述均来自阿里通义实验室 2026 年 3 月 Wan 2.7 官方发布材料以及 WaveSpeedAI API 文档。本文发布时,开源发布状态和官方定价均待确认,请分别前往阿里 Wan 官方 GitHub 和 wavespeed.ai 核实相关信息。
更多文章

AI图像代理:生成一张或百张图像 — 无需切换工具
NanoBanana 的AI图像代理可在单次对话中完成从单张概念图像到批量风格迁移的所有任务,无需prompt工程技术相关操作。

Veo 3.1 Lite Prompt 指南:20余个可直接使用的电影级AI视频Prompt
本文将详细教你如何运用prompt Veo 3.1 Lite制作出电影级效果。内容涵盖镜头类型、运镜、音频,以及20余个覆盖全流派、可直接复制粘贴的prompt,没有多余废话


Wan 2.7 对比 Wan 2.6:实际发生了哪些变化
Wan 2.7 新增了Wan 2.6没有的首尾帧控制、九宫格图像输入、multi-reference 视频和指令编辑功能。下文将实用分析两者的变化,以及不同场景下该如何选择。